


Research on Vibration Signal Classification Method of the Key Equipment of Reactor Based on Open-set Recognition
-
摘要: 在反应堆关键设备健康监测的实际工程场景下,设备状态随时间推移持续劣化,监测数据类别逐渐增多,传统数据驱动算法会出现准确度下降甚至失效问题。为克服这些问题,提出了一种开集信号分类方法。首先使用一个变分编码-分类器网络来对已知类别(KCs)进行分类,并学习特征空间的分布以提取隐特征;然后将隐特征拟合Weibull分布,基于极值理论(EVT)确定样本是否属于未知类别(UCs);最后使用反应堆实际运行过程中采集的多类带标签振动信号数据集进行模拟开集实验。实验结果表明,通过选取合适的判别阈值可对KCs和UCs进行有效地识别。本文方法为实际工程场景下,设备逐渐由正常状态出现未知故障的数据分类场景提供了可行的解决思路。Abstract: In the actual engineering scenario of health monitoring of key equipment in reactors, the equipment status continues to deteriorate over time, and the types of monitoring data gradually increase. Traditional data-driven algorithms may experience accuracy degradation or even failure. In order to overcome the above problems, this paper proposes an open set signal classification method. Firstly, a variational coding classifier network is used to classify known classes (KCs) and learn the distribution of feature space to extract hidden features; Then the hidden features are fitted to a Weibull distribution, and whether the sample belongs to unknown classes (UCs) is determined based on Extreme Value Theory (EVT); Finally, a simulated open set experiment is conducted using a multi-class labeled vibration signal dataset collected during the actual operation of the reactor. The experimental results show that by selecting appropriate discrimination thresholds, effective recognition of KCs and UCs can be achieved. The method proposed in this article provides a feasible solution for data classification scenarios where equipment gradually transitions from normal state to unknown faults in practical engineering scenarios.
-
Key words:
- Open-set recognition /
- Vibration signal /
- Health monitoring /
- Signal calssification
-
[1] ZHAO M, ZHONG S, FU X, et al. Deep residual shrinkage networks for fault diagnosis[J]. IEEE Transactions on Industrial Informatics, 2019, 16(7): 4681-4690. [2] KHAN S, YAIRI T. A review on the application of deep learning in system health management[J]. Mechanical Systems and Signal Processing, 2018, 107: 241-265. doi: 10.1016/j.ymssp.2017.11.024 [3] 雷亚国,何正嘉. 混合智能故障诊断与预示技术的应用进展[J]. 振动与冲击,2011, 30(9): 129-135. [4] 段智勇,刘才学,艾琼,等. 基于随机森林的屏蔽泵故障诊断方法研究[J]. 核科学与工程,2020, 40(4): 625-630. [5] NALISNICK E T, MATSUKAWA A, TEH Y W, et al. Do deep generative models know what they don’t know?[C]//Proceedings of the 7th International Conference on Learning Representations. New Orleans: OpenReview. net, 2019. [6] SCHEIRER W J, DE REZENDE ROCHA A, SAPKOTA A, et al. Toward open set recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(7): 1757-1772. doi: 10.1109/TPAMI.2012.256 [7] TAO Y, SHI H B, SONG B, et al. Hierarchical latent variable extraction and multisegment probability density analysis method for incipient fault detection[J]. IEEE Transactions on Industrial Informatics, 2022, 18(4): 2244-2254. doi: 10.1109/TII.2021.3090753 [8] RUFF L, VANDERMEULEN R A, GÖRNITZ N, et al. Deep one-class classification[C]//Proceedings of the 35th International Conference on Machine Learning. Stockholm: PMLR, 2018. -

 下载:
下载:








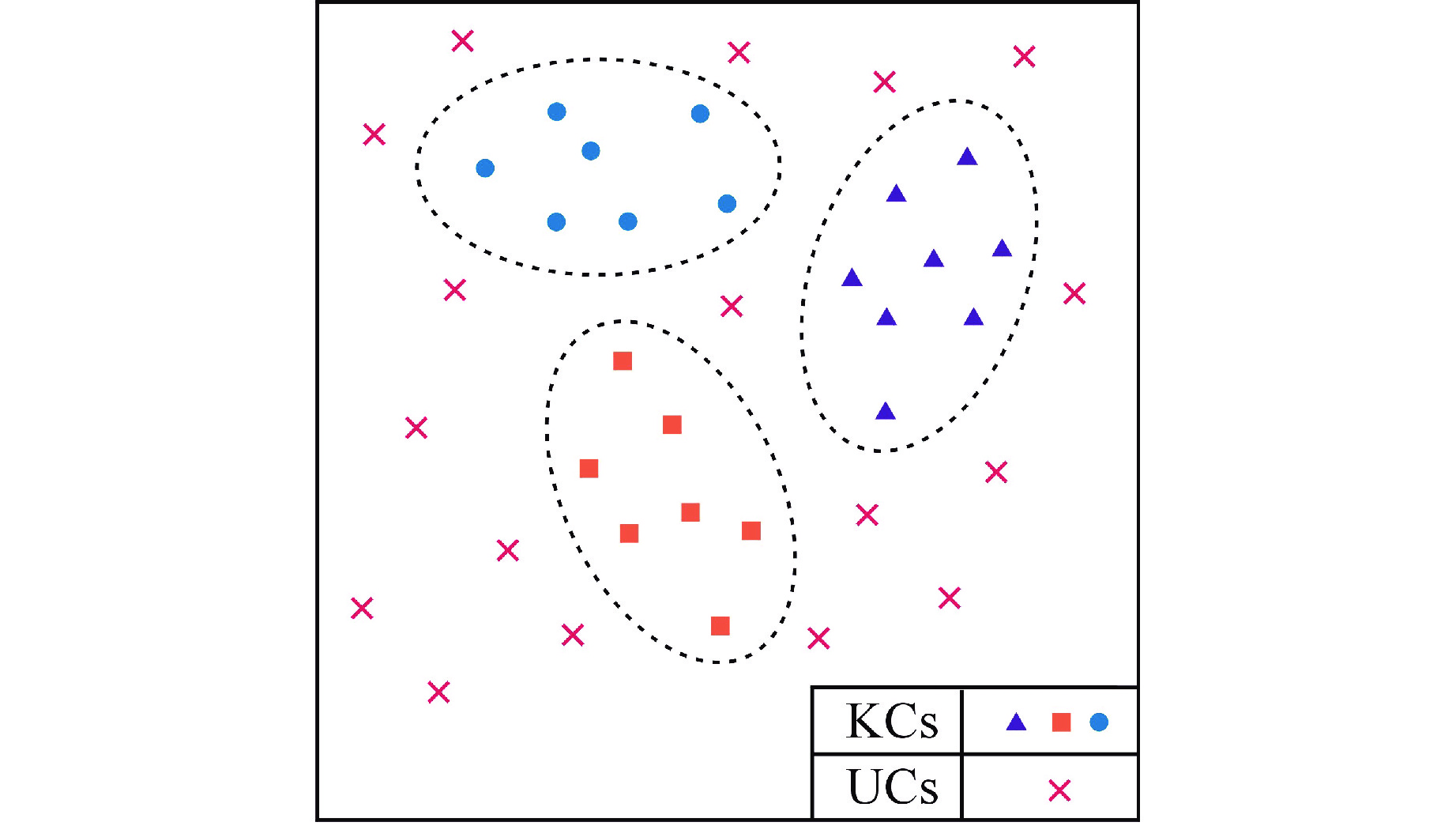
图(8)
计量
- 文章访问数: 123
- HTML全文浏览量: 65
- PDF下载量: 18
- 被引次数: 0
